Application Layer
An Overview
The Application Layer is the topmost layer in the Internet protocol suite. It defines the way software applications interact over the network. It allows users to send and receive data across a network.
Network Apps
Network apps run on different end systems and communicate over the network without requiring interaction with the network’s core devices (like routers). Examples → Social networking, web-browsing, email, video streaming etc.
Architecture: Client-Server vs. Peer-to-Peer
The Client-Server Paradigm
Consists of a server and a client.
- Server: A server is an always-on host with a permanent IP address. It’s often locaetd in data centers for better scaling.
- Clients: These are the ones that contact, and initiate communication with the server. Their connection may be intermittent and they may have dynamic IP addresses. Clients do not communicate with each other.
Peer-to-Peer Architecture
In this paradigm, there is no always-on server. There are arbitrary end-systems that communicate with each other directly. Peers request services from other peers who, and provide services in return to other peers and so on.
P2P is self scalable → As new peers bring new service capacity as well as new service demands.
Peers are intermittently connected and they change IP addresses often. This requires complex management.
Processes Communicating
A process is a program running within a host. Within the same host, two processes communicate using inter-process communication which is defined by the OS. Processes in different hosts communicate by exchanging messages.
Client processes are the ones who initiate the communication in this paradigm, and server processes are the ones that wait to be contacted by the clients.
Sockets
A socket is an interface that allows for communication between two processes, typically over a network.
Think of a socket as a door through which data is sent and recieved by an application process. It controls the in-and-outs of process communication.
The sending process prepares the message and sends it through its socket, it doesn’t actually handle the delivery. For the delivery, it relies on the transport layer to ensure that the message reaches its destination.
The receiving process has its own socket which is waiting to receive messages. Once the transport layer delivers the message to the receiving socket, the communication is complete. There always have to be 2 sockets involved.
Addressing Processes
- To receive messages, any process needs to have a unique identifier.
- The host devices has its own unique 32-bit IP address. This however is not enough for process identification, as there can be multiple processes running off of the same host.
- The identifier includes both the IP address and the port numbers associated with the process on the host.
Example port numbers:
- HTTP is on port 80.
- Mail servers are on port 25.
What does an application-layer protocol define?
An application-layer protocol defines the following:
- Types of Messages Exchanged: Request, Response etc.
- Message Syntax: What fields in messages and how fields are delineated.
- Message Semantics: The meaning of information in the fields.
- Rules for when and how processes send and respond to messages.
- Open Protocols: Defined in RFCs, allows for interoperability.
- Propreitary Protocols: Skype, Zoom.
What transport service does an app need?
- Data Integrity: Some apps require 100% reliable data transfer (such as file transfers, and web transactions) whereas other apps such as audio and video streaming can tolerate some loss.
- Timing: Some apps such as online gaming and calling require low delay to be ‘effective’.
- Throughput: Some apps such as multimedia require minimum amount of throughput to be effective. Other apps make use of whatever throughput they get.
- Security: Encryption and data integrity.
Internet Transport Protocol Services
TCP - Transmission Control Protocol
The following are the distinguishing features of TCP.
- Reliable Transport: TCP ensures that data is delivered reliably from the sender to the receiver. If any data is lost or corrupted during transmission, TCP detects it and retransmits until it is successfully delivered.
- Flow Control: TCP manages the flow of data between the sender and receiver to ensure that the sender does not overwhelm the receiver with too much data at once. It uses mechanisms like windowing to adjust the rate of data transmission based on the receiver’s capacity.
- Congestion Control: TCP dynamically adjusts the rate at which it sends data to avoid congestion. If the network is congested, TCP will slow down the transmission to prevent further congestion.
- Connection-Oriented: Before the data can be sent, TCP requires a connection to be established between the sender and receiver (often referred to as a three-way handshake). This setup ensures that both parties are ready to communicate and agree on all parameters like window size, sequence numbers etc.
- Does Not Provide Timing, Minimum Throughput, or Security: TCP does not guarantee real-time data delivery, minimum throughput or provide built-in security features like encryption.
UDP - User Datagram Protocol
- Unreliable Data Transfer: UDP provides unreliable communication, meaning it does not guarantee that the data will be delivered at all, or in the correct order. There is also no retransmission if the packets are lost.
- Does Not Offer: There is no flow control, congestion control or connection setup.
- Connectionless: UDP is connectionless which means that it does not require any handshake or setup between the sender and the receiver. This makes it faster since there is no overhead in establishing a connection before sending data.
- No Guarantees: UDP does not offer any built in guarantees regarding timing, data throughput or security.
Why Bother with UDP?
There are certain use cases where its simplicity and lack of overhead give it advantages over TCP:
- Speed: Makse it ideal for applications where speed is critical and occasional data loss is acceptable, such as live streaming, online gaming etc.
- Low Latency: It’s connectionless nature means it can provide low-latency communication which is crucial for VoIP and online gaming applications where delayed packets can cause noticeable disruptions.
- Efficiency for Small Data: For applications that send small, self-contained messages like DNS queries, UDP is more efficient as it avoids the overhead of connection setup and maintenance.
Securing TCP
Vanilla TCP & UDP Sockets have no encryption. Plaintext passwords that are sent into the socket traverse the entire Internet in plaintext with no encryption, which is unacceptable. That’s why we need to add security to the transport layer.
Transport Layer Security (TLS)
- It provides encrypted TCP connections.
- Guarantees data integrity.
- Has end-point authentication. TLS is implemented in the Application Layer. The apps use TLS libraries that use TCP in turn. The plaintext is sent into the socket, but traverse the Internet while encrypted.
Web and HTTP
Quick Review
- A webpage consits of objects, each of which can be stored on different web-servers. The object can be an HTML file, audio file, JPEG image, Java applet etc.
- The webpage consists of a base HTML-file which includes several referenced objects, each addressable by a URL.
HTTP Overview
HTTP or HypterText Transfer Protocol is the protocol used by the web to transfer web pages. It follows a Client-Server model:
- The client is the browser that requests and displays web objects (example → images, HTML files).
- The server is the one that sends objects in response to client requests.
HTTP Uses TCP
- A client initiates a TCP connection by creating a socket to a server at port 80.
- The server accepts the TCP connection from the client.
- HTTP messages, which are application-layer messages are exchanged between the browser and the web server.
- The TCP connection is then closed.
HTTP is Stateless
The server maintains NO information about past-client requests. Each request is treated independently. This simplicity avoids complications but can be inefficient for multi-step transactions, such as online purchases.
HTTP Connections
There are two types of HTTP connections.
- Non-Persistent HTTP (HTTP/1.0): A TCP connection is opened, following which at most one object is sent over the TCP connection, and then the TCP connection is closed. Downloading multiple objects require multiple connections.
- Peristent HTTP(HTTP/1.1): The TCP connection is opened to a server, following which multiple objects can be sent over a single TCP connection between client and that server. The TCP connection is then closed. HTTP 1.1 made persistent connections the default behavior.
Two types of persistent connections:
- Without Pipelining: After making an HTTP request, the client waits for the response before making the next request. There is still a delay bewteen each request-response pair because of the RTT. The client cannot send multiple requests in parallel, even though it uses the same TCP connection.
- With Pipelining: Requests are sent in parallel. The client can send multiple HTTP requests over a single TCP connection without waiting for corresponding responses. The responses however, must still arrive in the order in which the requests were sent.
Tracing a Non-Persistent HTTP Request
- The HTTP client initiates a TCP connection to the HTTP server at
www.someschool.eduon Port 80. - The HTTP server at the host is waiting for TCP connections at port 80. When it recieves it, it accepts the connection, notifying the client.
- Post-confirmation, the HTTP client sends HTTP request message (containing the URL) into the TCP connection socket. The message indicates that the client wants some object.
- The HTTP server receives the request message and forms a response message containing the requested object, and sends that message into its socket. Then it closes the TCP connection.
- The HTTP client receives the response message containing the HTML file
displays.html. After parsing, it finds 10 referenced .jpeg objects. It then repeats steps 1-5 for each of the 10 referenced .jpeg objects.
Non-Persistent HTTP - Response Time
RTT is the time taken for a small packet to travel from the client to the server and back.
HTTP Response Time (per object):
- One RTT to initiate the TCP connection
- One RTT for the HTTP request and first few bytes of HTTP response to return.
- Whatever time it takes for the object/file transmission.
Thus:
HTTP Messages
There are two types of HTTP messages, Request and Response.
HTTP Requests
An HTTP request message is sent by the client to the server, asking for resources like web pages, images or other content.
- POST Method: Sends data to the server, often used when submitting forms. Data is included in the body of the request.
- GET Method: Requests data from the server. It’s the most common method and doesn’t have a body.
- PUT Method: Uploads data to the server, often replacing existing resources with the new one.
- HEAD Method: Similar to GET but it only requests the headers. It is useful for checking resource availability or metadata (like content length) without downloading the entire body.
HTTP Response Message
An HTTP response message is sent by the server in response to a client’s request. It contains a status code to ifnorm the client whether the request was successful or if there were any errors. Some common HTTP response codes are:
- 200 OK: Request succeeded, requested object later in this message.
- 301 Moved Permanently: Requested object moved, new location specified later in this message.
- 400 Bad Request: The request message was not understood by the server.
- 404 Not Found: Requested document not found on this server.
- 505 HTTP Version Not Supported
Cookies
As we remember, HTTP interactions are stateless, which means that it doesn’t maintain any memory of past requests or interactions.
- Every HTTP request is treated as a single, isolated event.
- There is no multi-step transaction tracking. Once a request is completed, no data about that interaction is retained by the server.
- In case of a network failure or a client crash mid-transaction, there is no need for the server to ‘recover’ from it.
The Role of Cookies in Maintaining State
While HTTP is stateless by default, cookies are used by websites and browsers to maintain a session or state across multiple interactions.
There are 4 main components of cookies:
- Cookie Header in HTTP Response: When a server responds to an HTTP request, it may include a cookie in the response header. This cookie is a small piece of data that helps the server remember something about a user (example → a session ID).
- Cookie Header in Subsequent HTTP Requests: After receiving a cookie from the server, the browser stores it and automatically includes it in headers of future HTTP requests to the same server. This allows the server to identify the user and maintain continuity.
- Cookie File on the User’s Device: The browser stores teh cookies on the user’s device in a file. Each cookie is associated with a specific domain (example → amazon.com), and the browser sends the cookie back to teh domain for future interactions.
- Back-End Database on the Server :The server stores a record in its database that corresopnds to the cookie’s ID. This database contains information about the user’s session, preferences, or shopping cart, allowing the server to personalize future interactions.
Uses of Cookies
Cookies help websites perform a variety of functions to maintain state, such as:
- Authorization: Remember if a user is logged in.
- Shopping Carts: Keep track of the items a user has added to their carts across multiple sessions.
- Recommendations: Personalize content or recommend products based on browsing history.
- User Session State: Maintain the user’s state across interactions, such as with web-based email systems where the user stays logged in as they navigate.
Challenges in Maintaining State
Maintaining state across multiple HTTP transactions requires:
- At Protocol Endpoints: Both the client and the server must maintain information about the session (via cookies).
- In HTTP Messages: Cookies are sent with each HTTP request and response to carry session data back and forth between the client and the server.
How 3rd Party Cookies Work - An Example
Say I like reading travel blogs.
- Visit to makemytrip.com:
- I go to makemytrip.com, which sets a first-party cookie
session_id=ab123to remember my session. - Suppose this site uses AdSense, which sets a third-party cookie
ad_id=142to track my interests.
- I go to makemytrip.com, which sets a first-party cookie
- Clicking on an Ad: I click on an add for europeantrips.com and am redirected there. That site uses AdSense as well. My browser then sends the
ad_idcookie to europeantrips.com, which sends it to AdSense who recognizes the cookie and displays relevant ads.
This continues on all sites I visit and thus AdSense eventually builds a profile on me for targeted advertising.
Web Caching (Proxy Servers)
The goal here is to satisfy client requests without involving the origin server.
The user configures their browser to point towards a local web cache. The browser then sends all requests to the cache. If the object is stored in the cache, then it returns the object to the client, otherwise it requests the object from the origin server, caches the received object and then returns the object to the client.
Web cache acts as both the client and the server. It’s the server for the original client request, while acting as a client to the origin server. The advantage of web caching is that it reduces the response time for the client request, and it reduces the traffic on an institutition’s access link.
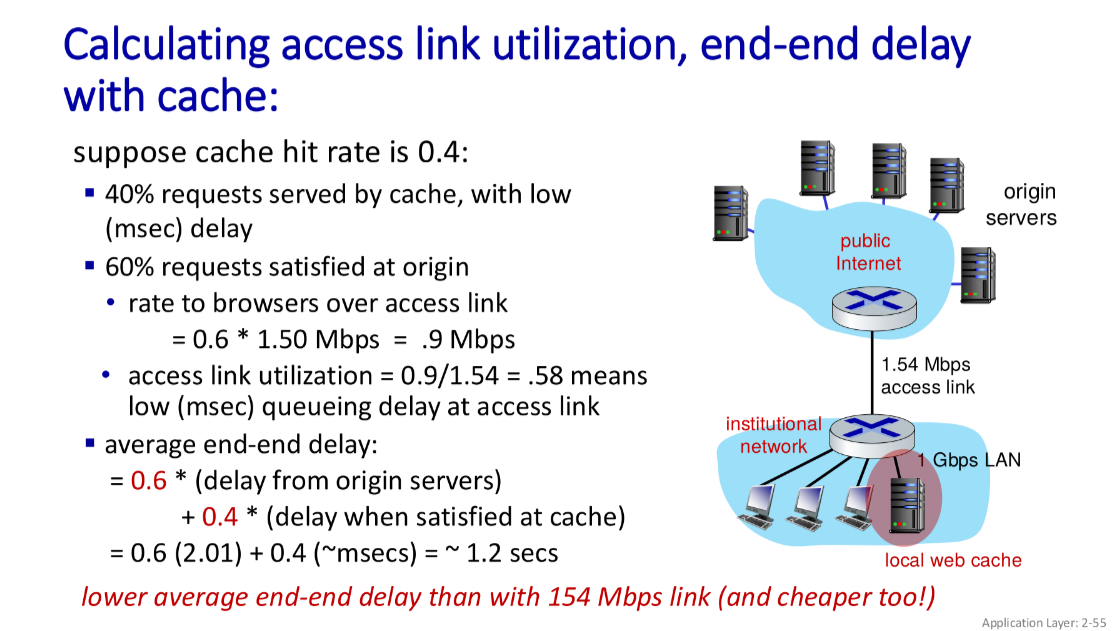
Check the numericals in the second PPT, slide 54 for revision.
Conditional GET
The goal here is to not send the object if the browser has an up-to-date cached version. The client specifies the date of browser-cached copy in the HTTP request. If the copy is up-to-date then the server response contains no object.
HTTP Versions
HTTP/2 - Decreased Delay in Multi-Object HTTP Requests
Key Goal → To reduce the latency experienced when a client requests multiple objects from a server.
HTTP/1.1 Limitations:
- Pipelining: HTTP/1.1 introduced the ability to send multiple pipelined GET requests over a single TCP connection.
- In-Order Reponses: Servers respond to requests in the order in which they were received.
- Head-Of-Line (HOL) Blocking: If a large object is requested first, smaller objects may experience delays waiting for the large object to be transmitted. This can lead to inefficiences and increased loading times.
- Loss Recovery: If TCP segments are lost, the retransmission process can stall the delivery of subsequent objects, further increasing delays.
Enhancements in HTTP/2
- Increased Flexibility: HTTP/2 maintains most methods, status codes and header fields from HTTP/1.1 but introduces significant enhancements in how data is transmitted. These are:
- Prioritization: Clients can now specify the priority of objects.
- Server Push: The server can proactively sends objects to the client before they are explicitly requested, anticipating future needs based on the current request.
- Frame-Based Transmission: Objects are divided into smaller frames, which can be interleaved and transmitted out of order.
HTTP/2 - Mitigating HOL Blocking
In HTTP/1.1, when a client requested one large object and three smaller objects, the server must deliver them in the order in which they were requested, causing delays for smaller objects. However, HTTP/2 allows the server to divide the requested objects into frames, enabling interleaved transmission.
HTTP/2 to HTTP/3
HTTP/2 over a single TCP means that recovery from packet loss still stalls all object transmissions, and there is no security over a vanilla TCP connection. HTTP/2s way of dealing with this was to open multiple parallel TCP connections, which could complicate resource management and increase the overhead.
In HTTP/3, it’s mainly UDP based, which provides advantagse such as reduced latency and more efficient error-and-congestion-control on a per-object basis. There is also improved security with built-in security features.
Email, SMTP and IMAP
An Overview
Everyone is familiar with email. It consists of 3 main components:
- User Agents (UAs)
- Mail Servers
- Simple Mail Transfer Protocol (SMTP)
1. User Agents (UAs)
A user agent is also known as a ‘mail reader’. It is a software that enables users to compose, edit and read email messages. Popular examples include Outlook, Gmail and Apple Mail. Contains the following functionality:
- Composing & Sending
- Receiving & Reading
- Storage
2. Mail Servers
Mail servers handle all the sending and receiving of email messages. Each user has a mailbox on the server. It’s components include:
- Mailbox: This contains all incoming messages for a specific user.
- Message Queue: Stores outgoing mail messages until they are delivered.
Mail servers use the SMTP protocol to send email messages between themselves.
3. Simple Mail Transfer Protocol (SMTP)
It’s the protocol used to send email messages from a client to a mail server and between mail servers. RFC 5321: This specification defines how SMTP operates over TCP, typically on port 25.
Phases of SMTP Transfer:
- SMTP Handshaking: Estabilshes the connection between the two servers.
- SMTP Transfer of Messages: Actual transfer occurs.
- SMTP Closure: Properly terminates the connection.
SMTP Observations
A comparison with HTTP:
- Direction: HTTP is client-pull, SMTP is client-push.
- Command Structure: Both use ASCII command/response formats and status codes.
- Message Handling HTTP sends each object in its own response, while SMTP can send multiple objects in a multipart message.
- Connections: SMTP uses persistent connections, maintaining open links
- Message Format: SMTP requires messages to be in 7-bit ASCII foramt, using CRLF to signal the end of a message.
Mail Message Format
The header lines require essential metadata such as the To, From and Subject fields along with the actual Body of the email message, composed of ASCII characters only.
Retrieving Email : Mail Access Protocols
- IMAP: Messages are stored on the server. It allows retrieval, deletion and management of stored messages in folders.
- POP (Post Office Protocol): Another common retrieval method, often simpler than IMAP, allowing users to download messages to their local device.
- HTTP: Web-based interfaces (example → Gmail, Yahoo! Mail) use HTTP on top of SMTP for sending and IMAP (or POP) for retrieving messages.
The Domain Name System (DNS)
DNS is a crucial part of the Internet, responsible for translating human-readable domain names into machine-readable IP addresses. It is a distributed, hierarchical system designed to handle billions of records and process trillions of queries each day, ensuring efficient and reliable communication between hosts on the Internet.
Identifiers in DNS
Internet hosts and routers have identifiers:
- IP Address; A unique 32-bit number used to address datagrams in the network.
- Domain Name: A human-readable identifier like
cs.umass.edu.
What is DNS?
DNS is:
- A distributed database implemetned across a hierarchy of name servers.
- An application-layer protocol used by hosts and DNS servers to communicate for resolving names.
DNS Services
DNS provides several essential services:
- Hostname-to-IP-Address Translation; Translates human-readable domain names into machine readable IP Addresses.
- Host Aliasing:
- Canonical Names: The primary names for hosts.
- Alias Names: Alternative names for the same host.
- Mail Server Aliasing: Provides aliasing for mail servers.
- Load Distribution: Distributes load across replicated web servers by allowing multiple IP addresses to correspond to a single domain name.
Why Not Centralize DNS?
This wouldn’t wor kdue to several limitations, such as:
- Single Point Of Failure
- Traffic Volume: A central server would be overwhelmed by global DNS traffic.
- Geographical Distance
- Maintenance: Maintaining a single centralized database would be inefficient and impractical. Thus, DNS is decentralized/distributed to ensure scalability.
DNS Structure & Hierarchy
DNS is organized hierarchically:
- Root DNS Servers: These are at the to plevel. They serve direct queries to top level domain servers.
- Top Level Domain (TLD) Servers: Responsible for domains like
.com,.org,.edu,.inetc. - Authoritative DNS Servers: Organization’s own DNS server(s), provide the IP address for the requested domain, such as
www.amazon.com.
An example of a DNS query resolution:
- Client requests a root server to find the
.comDNS server. - The
.comDNS server directs the client toamazon.com’s DNS server. amazon.com’s DNS server returns the IP address ofwww.amazon.com.
Local DNS Servers
Local DNS serers are typically managed by the ISPs and play a key role in resolving DNS queries:
- When a host makes a DNS query, it is first sent to the local DNS server.
- The local server may:
- Return the result from cache (if available), or
- Forward the query into the DNS hierarchy if it cannot resolve the name locally.
Local DNS servers do not strictly belong to the DNS hierarchy, but rather act as intermediaries.
DNS Query Resolution: Iterative and Recursive Queries
- Iterative Query: The DNS server returns the address of another DNS server that may know the answer and the client continues the query.
- Recursive Query: The DNS server takes full responsibility for resolving the query, querying other servers if necessary and returning the final IP address to the client. THis puts more load on higher-level DNS servers.
DNS Caching
DNS servers cache name-to-address mappings to improve performance:
- Cached entries have a TTL (Time-to-Live), after which they expire.
- Cached entries may be out of date if the IP address of the host changes before the TTL expires.
DNS Records
DNS servers store Resource Records (RRs) in the format (name, value, type, ttl). Some important types include:
- A Record: Maps a hostname to an IP address.
- NS Record: Specifies the authoritative name server for a domain.
- CNAME Record: Maps an alias name to the canonical (real) name.
- MX Record: Specifies the mail server for a domain.
DNS Protocol Messages
DNS uses query and reply messages, both of which have the same format. These messages include:
- Header: Contains a 16-bit identification number and flags indicating whether it’s a query or reply, recursion settings, etc.
- Question Section: Contains the query name and type.
- Answer Section: Contains resource records (RRs) answering the query.
DNS Security
DNS faces several security threats:
- DDoS Attacks
- Spoofing Attacks
- DNS Cache Poisoning: Attacking a cache with malicious entries to mislead users.
DNSSEC helps combat these threats by providing authentication and message integrity.
P2P Applications
We’ve explored this before in this note:
Transclude of #peer-to-peer-architecture
File Distribution Time
File Distribution Time in Client-Server Model
- Server Transmission: The time required to upload copies is where is the file size, and is the server’s upload rate.
- Client Download Time: Each client needs at least to download the file, where is the minimum client download rate.
- Total Time: Thus the total time taken to distribute the file is the max of the server transmission and the client download time.
- As the number of clients increases, the distribution time increases linearly.
File Distribution Time in P2P Model
- In P2P file distribution, the server uploads only one copy of the file and the peers share it among themselves.
- Server Transmission: The server must upload one copy of the the file, requiring time .
- Client Download Time: Each client needs at least to download the file.
- Peer Contribution: As peers receive parts of the file, they can begin sharing those parts with other peers, contributing to the overall upload capacity.
- The total available upload capacity in the system is: